This is the second part in the series as a follow on to /log-aggregation-aws-part-1/
Hopefully by this point you’ve now got kibana up and running, gathering all the logs from each of your desired CloudWatch groups. Over time the amount of data being stored in the index will constantly be growing so we need to keep things under control.
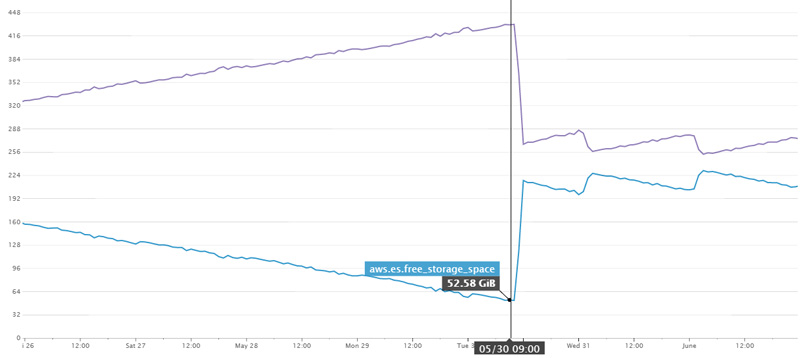
Here is a good view of the issue. We introduced our cleanup lambda on the 30th, if we hadn’t I reckon we’d have about 2 days more uptime before the disks ran out. The oscillating items from the 31st onward are exactly what we’d want to see – we delete indices older than 10 days every day.
Initially this was done via a scheduled task from a box we host – it worked but wasn’t ideal as it relies on the box running, potentially user creds and lots more. What seemed a better fit was to use AWS Lambda to keep our index under control.
Getting setup
Luckily you don’t need to setup much for this. One AWS Lambda, a trigger and some role permissions and you should be up and running.
- Create a new lambda function based off the script shown below
- Add 2 environment variables:
- daysToKeep=10
- endpoint=elastic search endpoint e.g. search-###-###.eu-west-1.es.amazonaws.com

- Create a new role as part of the setup process
- Note, these can then be found in the IAM section of AWS e.g. https://console.aws.amazon.com/iam/home?region=eu-west-1#/roles
- Update the role to allow Get and Delete access to your index with the policy:
-
12345678910111213{"Version": "2012-10-17","Statement": [{"Effect": "Allow","Action": ["es:ESHttpGet","es:ESHttpDelete"],"Resource": "ARN of elastic search index"}]}
- Setup a trigger (in CloudWatch -> Events -> Rules)
- Here you can set the frequency of how often to run e.g. a CRON of
10 2 * * ? *
will run at 2am every night
- Here you can set the frequency of how often to run e.g. a CRON of
- Test your function, you can always run on demand and then check whether the indices have been removed
And finally the lambda code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 |
var AWS = require('aws-sdk'); var endpoint; var creds = new AWS.EnvironmentCredentials('AWS'); Date.prototype.addDays = function(days) { var dat = new Date(this.valueOf()); dat.setDate(dat.getDate() + days); return dat; } exports.handler = function(input, context) { endpoint = new AWS.Endpoint(process.env.endpoint); let dateBaseline = new Date(); dateBaseline = dateBaseline.addDays(-parseInt(process.env.daysToKeep)); console.log("Date baseline: " + dateBaseline.toISOString()); getIndices(context, function(data) { data.split('\n').forEach((row) => { let parts = row.split(" "); if (parts.length > 2) { let indiceName = parts[2]; if (indiceName.indexOf("cwl") > -1) { let indiceDate = new Date(indiceName.substr(4, 4), indiceName.substr(9, 2)-1, indiceName.substr(12, 2)); if (indiceDate < dateBaseline) { console.log("Planning to delete indice: " + indiceName); removeIndice("/"+indiceName, context); } } } }); }); } function removeIndice(indiceName, context) { makeRequest("DELETE", indiceName, context); } function getIndices(context, callback) { makeRequest("GET", '/_cat/indices', context, callback); } function makeRequest(method, path, context, callback) { console.log(`Making ${method} call to ${path}`); var req = new AWS.HttpRequest(endpoint); req.method = method; req.path = path; req.region = "eu-west-1"; req.headers['presigned-expires'] = false; req.headers['Host'] = endpoint.host; var signer = new AWS.Signers.V4(req, 'es'); signer.addAuthorization(creds, new Date()); var send = new AWS.NodeHttpClient(); send.handleRequest(req, null, function(httpResp) { var respBody = ''; httpResp.on('data', function(chunk) { respBody += chunk; }); httpResp.on('end', function(chunk) { if (callback) { callback(respBody); } //console.log(respBody); }); }, function(err) { console.log('Error: ' + err); context.fail('Lambda failed with error ' + err); }); } |
Note, if you are running in a different region you will need to tweak req.region = “eu-west-1”;
How does it work?
Elastic search allows you to query the index to find all indices via the url: /_cat/indices. The lambda function makes a web request to this url, parses each row and finds any indices that match the name: cwl-YYYY.MM.dd. If an indice is found that is older than days to keep, a delete request is issued to elasticSearch
Was this the best option?
There are tools available for cleaning up old indices, even ones that Elastic themselves provide: https://github.com/elastic/curator however this requires additional boxes to run hence the choice for keeping it wrapped in a simple lambda.
Happy indexing!
Thanks, this was extremely useful. Simple and to the point.
Hi,
Nice article.
I am newbie. When you create Lambda function what type of Runtime do we have to select (c#, java 8, node.js 4.3, jode.js 6.10, python 2.7, python 3.6)
Do we have to specify VPC and Subnet for this when we creating the function.
Finally, how do test this please manually. Detail steps would be very helpful.
Many thanks
These functions are done in javascript so would be node. We run as 4.3.
You can leave the VPC (and subnet) blank, unless you need to run within a secure network you own.
To test the function you can run from within the AWS console, rather than waiting for the timed trigger to kick in.